1.生成AIへの期待
ChatGPTの公開後、現在に至るまで、生成AIへの期待は膨らみ続けている。わずか2年足らずの間に、メガプラットフォーマーを中心とした様々な企業から、より大規模なパラメータを持つLLMが、あるいは使い勝手の良いコンパクトなLLMがつくられており、文書、画像、音楽、そして動画といったコンテンツの自動生成が、それこそ魔法のように可能になり始めている。
生成AIの出現によって、人間の労働時間の60~70%が自動化され、世界全体としての生産性向上へのインパクトは、イギリスのGDPに匹敵する年間2.6~4.4兆ドルにも達するという指摘もある[1]。生成AIが、近年に出現した技術の中で桁外れのポテンシャルを持っているのは間違いなさそうだ。
生成AIは自然言語による指示によって動作するため、その活用範囲はホワイトカラー全体に及ぶ。特に、過去の自動化技術が適用しにくかったクリエイティブな職種が行う業務や、コミュニケーションを伴う業務において大きな効果が期待できる。また、これまでの自動化技術がスキルレベルの低い労働者に大きな影響を与える傾向を持つのに対して、生成AIは全く逆のハイレベルの労働者が行う専門的な業務を強力に支援できるという特徴があることにも注目したい。OpenAIによる研究でも、参入障壁が高く専門性が高い職種になればなるほど、生成AIの影響が大きくなるという報告がなされている[2]。賃金の高い高度な知識労働者が行っている業務ほど、生成AIのインパクトが大きいということはかなり興味深い。
2.生成AI活用に消極的な日本
日本における生成AIの活用は、足元ではそれなりに進みつつあるようだ。PwCコンサルティングの調査によれば、自社の生成AI活用の推進度合いについて、「活用中もしくは推進中」である企業が2023年春に8%でしかなかったのに対して、2024年春には67%に上昇している[3]。
しかし、世界全体と比較すると日本における生成AIの活用はまだまだ不十分だという指摘が多い。MicrosoftとLinkedInの共同調査では、知的労働者における生成AIの業務利用割合は、世界平均が75%に対して、日本は32%とかなり低い。また「競争力を保つにはAIが必要と考えている経営者の割合」、「AIスキルのない人材は採用しないと考える経営者の割合」、「業務経験は浅いがAIスキルのある候補者を、業務経験豊富だがAIスキルのない候補者よりも優先して雇用すると考える経営者の割合」のいずれについても、日本は調査対象国中最下位になっている[4](図表1参照)。先に述べたように、スキルレベルの高い業務であるほど大きな影響を及ぼすという生成AIの特性を考えると、日本の経営者における意識の低さはかなり気になる。
図表1 消極的な日本の生成AI導入状況
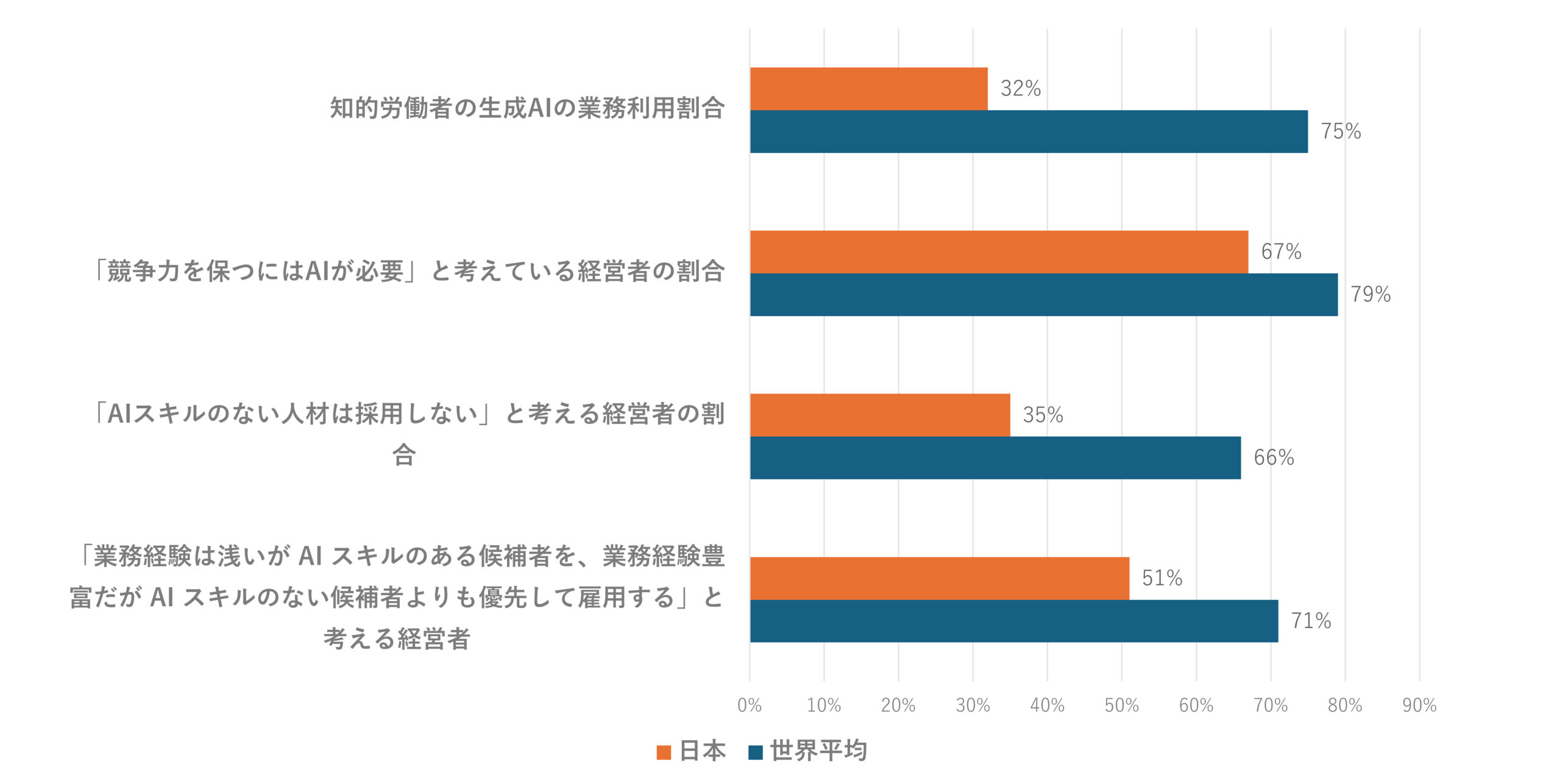
(出典)Microsoft・LinkedIn“2024 Work Trend Index Annual Report”
周囲の状況を見る限り、日本の多くの企業あるいは行政機関において、生成AIを社員や職員に活用させようとする動きはそれなりに活性化しているように見える。ただし、あくまでも一人ひとりが自らの仕事を行う上で、生成AIを使うというレベルに留まっているようだ。組織の業務全体に生成AIを組み込んで抜本的な省力化を行ったり、顧客向けのサービスをつくったりするところまで至っているケースはまだまだ少ない。
3.生成AI活用のためのデータ環境整備
最近の企業事例を見ると、生成AIの活用の仕組みにはいくつかの段階があるようだ。第1段階は、汎用のLLMをそのまま使うというものだ。ChatGPT等に、多少セキュリティ対策を施しながら、組織内の人が利用できるようにする。使い勝手を良くするために、目的ごとのプロンプトを整備したりすることもあるが、基本的には個人が自らの裁量で生成AIを使う形になる。第2段階は、汎用LLMの活用に自組織の独自性を付け加える形だ。RAG(Retrieval Augmented Generation:検索拡張生成)という技術が用いられることが多い。RAGは、汎用LLMから自組織内の情報を整理したデータベースを参照させることで、より自組織の業務内容にフィットした、正確で有益な回答を得られるようにする技術である。例えば、自組織の業務マニュアルや、顧客情報等を検索する独自サービスをつくり出すこと等が行われている。また、さらに難易度は上がるが、汎用LLMを、特定の目的に対応させるために、自組織で準備したデータを追加学習させてカスタマイズするファインチューニングという技術もある。そして、第3段階は、自組織で用意した巨大なデータをもとに、独自のLLMを新しくつくることだ。独自LLMの製造は、国内でも専門的な技術を保有している先進的企業でいくつか行われてはいるものの、一般的な組織ではかなりハードルは高い取り組みだ。従って、「単なる生成AIとの会話」という段階を超えて、高度なサービスを構築するためには、第2段階を狙う必要がある。重要なのは、生成AIと連携するための自組織独自のデータを用意できるかどうかということになる。
前出のPwCコンサルティングの調査では、自社内での生成AIの活用において「期待以上の成果を上げられた要因」の第2位に「生成AIにインプットするデータが十分に整備されていた、もしくはデータ整備を十分に行った」ということがあげられている。さらに「期待以上の成果を上げられなかった要因」の第1位には「生成AIにインプットするデータが不十分または質が低く、アウトプット品質に影響を与えた」ということがあげられている[3](図表2参照)。まさに、自組織内のデータの整備状況が生成AIの高度な活用の鍵だといえる。
図表2 生成AI活用で期待以上の成果が上げられた要因・上げられなかった要因

(出典)PwCコンサルティング「生成AIに関する実態調査2024春」
4.データ整備が不十分な日本
残念ながら日本の多くの組織において、データの整備状況が不十分で、活用しにくい環境にある。これは、以前から指摘されている大きな課題である。
情報処理推進機構が行った日米比較調査によれば、「部門間で標準化したデータ分析基盤がある」「社内外の様々なソースから柔軟にデータ収集・蓄積が可能である」「必要で適切な情報を必要なタイミングで取り出せる」という質問項目に対して、日米ともにその重要性は強く認識しているが、具体的な達成度については、米国がかなり高いのに対して日本ははるかに低いことがわかる[5](図表3参照)。重要であることを十分理解していながら、達成することができないという状況からも、この課題の根の深さが想像できる。
図表3 データ活用の重要度と達成度(日米比較)
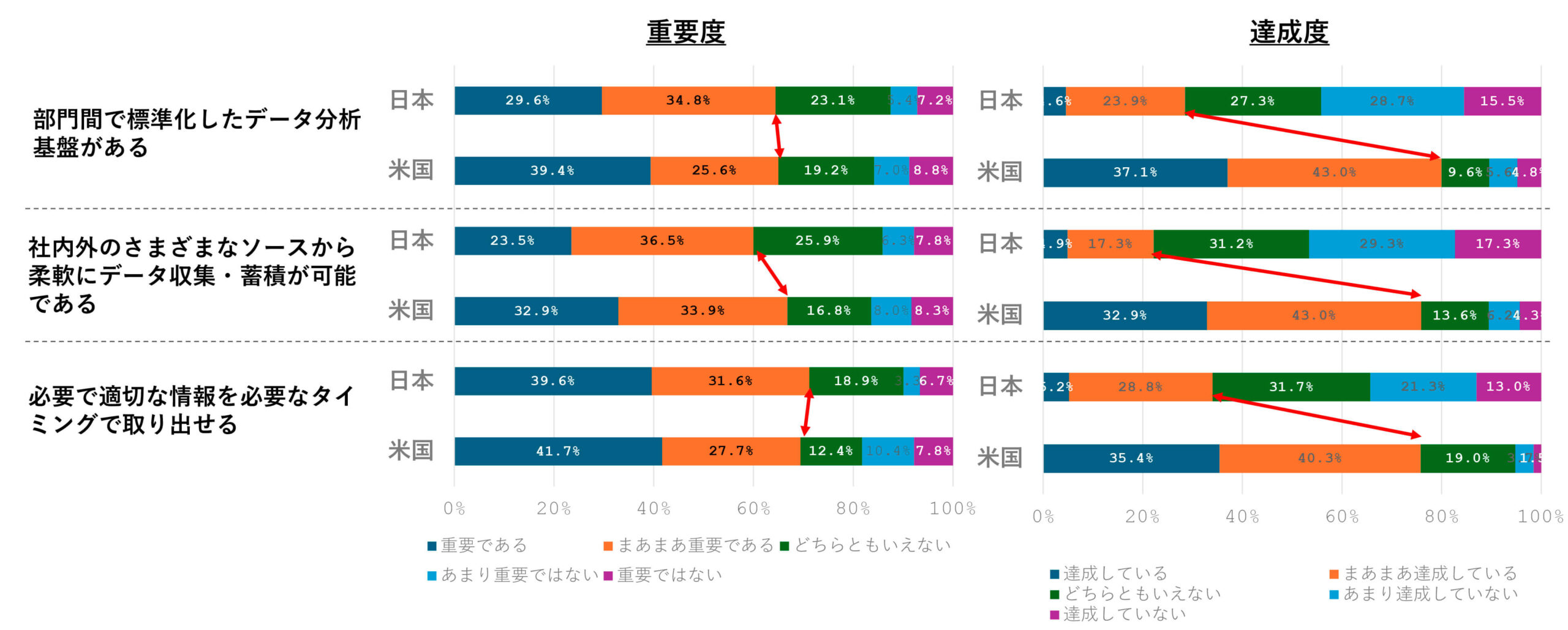
(出典)「DX白書2023」(情報処理推進機構)
この課題には日本社会独自の背景があるのも事実だろう。終身雇用を前提としているため、社会全体としての人材流動性が低いので、同じ業務であっても、企業ごとにあるいは行政機関ごとに業務プロセスが異なり、データ名称も異なることが多い。また、同じ人材が長期間同じ企業等に所属しているため、業務に関する知識やノウハウが属人化していて、可視化し共有するインセンティブが弱い。このような環境では、業務に必要なデータが不明確になり蓄積がしにくくなる。
また、情報システムの導入が現場主導で行われる傾向が強く、データが現場にある個別の業務ごとに扱われてしまう傾向もある。結果的に組織全体としてデータの標準化が進まなくなる。
必要なデータが十分に蓄積され整備されていることは、生成AIの活用だけでなく、いわゆるデータドリブン経営を目指す上でも、ビッグデータを活用した新しいサービスをつくる上でも、さらにはSociety5.0のような、あらゆる主体間をデータが連携するような環境を構築するためにも欠かすことができない重要なことである。組織全体におけるデータ整備は早急に取り組むべき大きなテーマだと考える。
5.データ品質とは
必要なデータが整備されている度合いを「データ品質」という言葉で示すことがある。それでは「データ品質が高い」というのは具体的にどのような状況を意味するのだろうか。
デジタル庁が、データ品質の客観的な評価を行うためにまとめた「データ品質管理ガイドブック」によれば、データ品質は、「データ(自体の)品質」と「サービス品質」、そして「データ管理プロセス品質」の3つから構成されるという[6]。
「データ(自体の)品質」は、具体的には、「正確性(Accuracy)」、「完全性(Completeness)」、「一貫性(Consistency)」、「信ぴょう性(Credibility)」、「最新性(Currentness)」等、15項目がある(図表4参照)。
図表4 データ品質の内容(ISO/IEC 25012による)
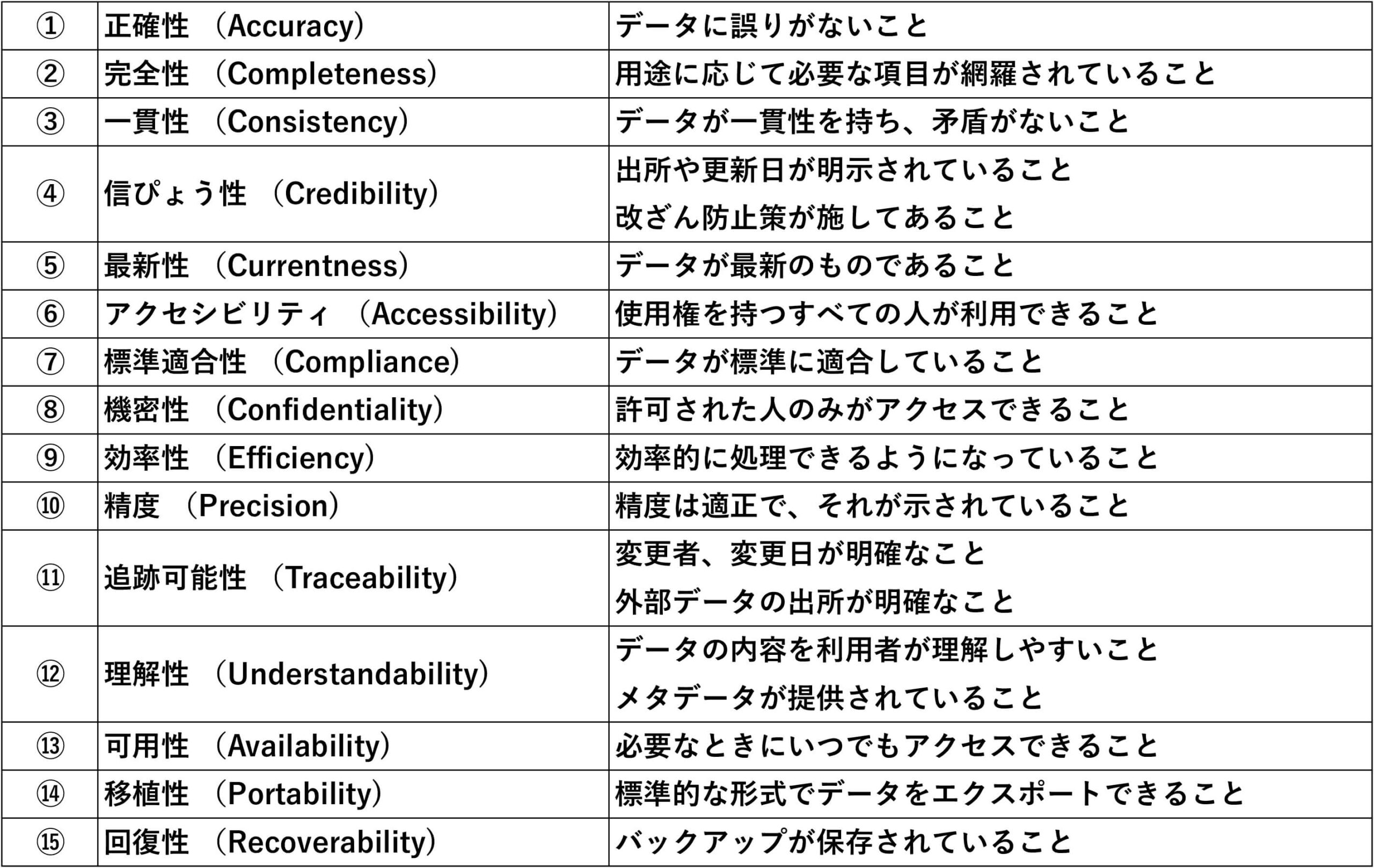
(出典)ISO/IEC 25012をもとに作成
また、「サービス品質」は、データを使ったサービスを実現するために関連するプロセス全体に関する品質のことをいう。ISO/IEC 25024によれば、サービス品質は「サービス管理」「サービス消費」「サービス提供」の3つのカテゴリーから成り立っている。「サービス管理」は、データ設計、データ収集、データ処理等といったステップから構成されるもので、目的に適うように設計し、ガバナンスを効かせることでサービス品質を向上させるものだ。また、「サービス消費」は、外部データ取得と外部サービス利用から成り立つもので、品質の高い外部データや汎用サービスを使うことで処理自体のサービス品質を向上させることをいう。「サービス提供」は、公開やその他の利用といったプロセスから構成されるもので、様々なチャネルや方法を使うことでサービス品質を向上させることをいう。
さらに「データ管理プロセス品質」は、データに関する管理を行うプロセスに関する品質のことを指す。ISO/TS 8000-61によれば、データ管理プロセス品質は、「データ品質計画」「データ品質管理」「データ品質保証」「データ品質改善」という連続するプロセスや、それをサポートする「データアーキテクチャ管理」「データセキュリティ管理」等、そしてリソースに関連する「データ品質管理組織の管理」「人材管理」から構成される。
また、データ品質を維持管理することができる組織がどうかを、「データ成熟度」という指標で評価することも行われている。評価のフレームワークは世界中から複数の提案がなされている状況にある。(例えば、ISACAのCMMI Instituteが作成したDMM(Data Management Maturity:データマネジメント成熟度モデル)や、イギリスの調査会社Data Orchardが開発したData maturity framework等がある)
6.データ品質向上のためのポイント
実際に組織におけるデータ品質を向上させるために留意すべきポイントについていくつか述べていく。
(1)データ戦略をつくる
データに特化した戦略を保有している組織は少ないとは思うが、これはぜひ策定してほしい。データ品質の向上は、各現場や、個別の情報システムからボトムアップに行うのではなく、トップダウンで実施すべきことである。従って、組織全体としてデータを活用することにより何を目指すのかというビジョンや、それを実現するための戦略が必要になる。前にも述べたように、データ品質を向上させる目的は生成AIの活用以外にも複数存在する。また、管理対象となるデータは膨大にある。限られた予算やリソースの中で、どの目的でどの領域のデータ品質を向上させるかの優先順位付けが不可欠であり、この観点からもデータ戦略が必要になる。
(2)データマネジメントを推進する
組織全体として「データマネジメント」を開始してほしい。
データマネジメントとは、「ビジネスや公共の活動における成果(価値)を最大化させるため、データの重要性に着目し、データを情報資産として捉え、その利活用戦略からシステム実装に向けた設計や開発、さらに稼働後の運用、利用に至るまでのデータ品質の維持・向上をベースとした継続的、組織的な活動」のことをいう[7]。
重要なのは、データをつくり出すところからそれを廃棄するまでの、プロセス全体をEnd to Endで管理することだ。近年のデータサイエンスブームを経て、「データ分析」が重要な業務としてクローズアップされているが、データ品質を向上させていくためには、それだけでなくデータそのものを作り上げるプロセスから考えていく必要がある。情報システム開発において、従来一部の企業で行われてきた「データ中心設計(DOA:Data Oriented Approach)」と呼ばれる開発手法の導入も改めて検討する余地がありそうだ。
(3)専門組織をつくり専門人材を育成する
データマネジメントのための専門組織をつくることもお勧めしたい。データマネジメントは各現場バラバラでは行えない横断的な業務であること、さらには個々の情報システムの寿命をはるかに超えて長期間にわたって継続的に管理を行わなければならない性格上、既存組織のどこかが片手間に行うのではなく、組織から認められた公式の組織を新設することが有効だと考える。(中央省庁においても、デジタル庁がこの位置づけになり、各省庁で扱っているデータを横断的にマネジメントできるようになるといいのだが)
また、データ品質向上のための作業は、各々の組織にとっては短期的成果につながらない面倒なことのように見えやすい。従って、ある程度各組織への強制力を持つことが不可欠になる。この点からも独立した専門組織を立ち上げることは意味がある。
加えて、データマネジメントを行うためのスキルを保有する人材を早急に育成すべきと考える。データベースの設計技術者やデータサイエンティストは一定数いるとしても、データの作成から分析・廃棄までの全プロセスを対象にして管理できるような人材は多くはないだろう。必要なスキルセットやノウハウを整理し、育成の仕組みをつくるとともに、実際にデータマネジメントを行う現場で経験を積ませていく必要がある。
繰り返しになるが、データ品質が不十分であることは、以前からわかっていた日本の組織の共通的な弱点の一つだ。「生成AIの高度活用」という新しい魅力的な目標を、対応が後回しになっていたこの課題を克服するための千載一遇のチャンスだと前向きに受け取っていただきたい。
【参考文献】
[1] Mckinsey & Company「生成AIがもたらす潜在的な経済効果」2023年
[2] Tyna Eloundou, Sam Manning, Pamela Mishkin, Daniel Rock「GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models」 2023年
[3] PwCコンサルティング「生成AIに関する実態調査2024春」2024年
[4] Microsoft・LinkedIn「2024 Work Trend Index Annual Report」2024年
[5] 情報処理推進機構「DX白書2023」2023年
[6] デジタル庁「データ品質管理ガイドブック」2022年
[7] デジタル庁「データマネジメント実践ガイドブックについてのお知らせ」2023年

三谷 慶一郎(みたに けいいちろう)
株式会社NTTデータ経営研究所
主席研究員 エグゼクティブ・コンサルタント
企業や行政機関におけるデジタル戦略やサービスデザインに関するコンサルティングや調査を推進している。博士(経営学)。武蔵野大学国際総合研究所客員教授、情報社会学会理事、経営情報学会監事、日本システム監査人協会副会長。近著に「ITエンジニアのための体感してわかるデザイン思考」(日経BP)、「攻めのIT戦略」(NTT出版)、監訳書に「DX経営戦略」(NTT出版)がある。

